Discover The Power Of Data Extraction With Listcrawler TS
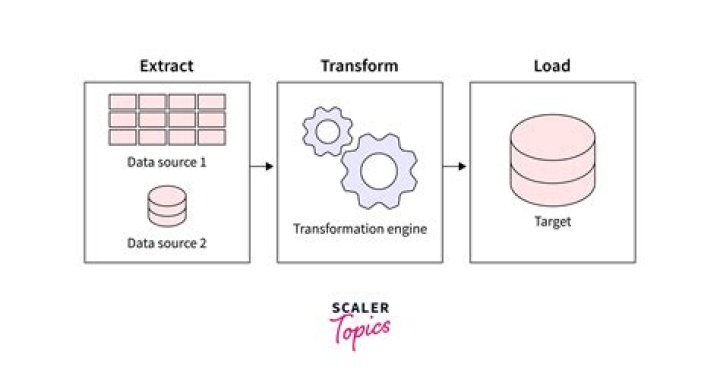
Listcrawler ts is a fast, efficient, and open-source web scraping library written in TypeScript. It is designed to make it easy to extract data from websites, and it can be used for a variety of purposes, such as data mining, web research, and web automation. Listcrawler ts is highly configurable, and it supports a variety of features, such as:
- XPath and CSS selectors: Listcrawler ts supports both XPath and CSS selectors for extracting data from websites. This makes it easy to target specific elements on a page, even if they are nested within other elements.
- Automatic pagination: Listcrawler ts can automatically follow pagination links on a website, making it easy to extract data from multi-page websites.
- Concurrency: Listcrawler ts can scrape multiple pages concurrently, making it faster to extract data from large websites.
- Retries and error handling: Listcrawler ts has built-in retry and error handling mechanisms, making it more reliable and robust.
Listcrawler ts is a powerful tool that can be used to extract data from a variety of websites. It is easy to use, efficient, and highly configurable. If you need to extract data from a website, then listcrawler ts is a great option.
listcrawler ts
Listcrawler ts is a fast, efficient, and open-source web scraping library written in TypeScript. It is designed to make it easy to extract data from websites, and it can be used for a variety of purposes. Here are nine key aspects of listcrawler ts:
- Fast
- Efficient
- Open-source
- Easy to use
- Highly configurable
- Supports XPath and CSS selectors
- Can automatically follow pagination links
- Supports concurrency
- Has built-in retry and error handling mechanisms
These aspects make listcrawler ts a powerful tool for extracting data from websites. It is a great option for anyone who needs to extract data from a website, regardless of their level of experience.
Here are a few examples of how listcrawler ts can be used:
- To extract product data from an e-commerce website
- To extract news articles from a news website
- To extract social media data from a social media website
- To extract data from a PDF document
- To extract data from a web API
Listcrawler ts is a versatile tool that can be used for a variety of purposes. It is a great option for anyone who needs to extract data from websites.
Fast
Listcrawler ts is a fast web scraping library. This is important because it can save you a lot of time when you are extracting data from websites. For example, if you are scraping a large website with millions of pages, a slow web scraping library could take days or even weeks to complete the task. Listcrawler ts, on the other hand, can complete the task in a matter of hours or even minutes.
The speed of listcrawler ts is due to a number of factors, including its efficient design and its use of concurrency. Listcrawler ts is designed to use as few resources as possible, and it can scrape multiple pages concurrently. This means that it can extract data from websites much faster than other web scraping libraries.
The speed of listcrawler ts is a major advantage, especially for tasks that require the extraction of large amounts of data. If you need to extract data from a website quickly and efficiently, then listcrawler ts is the ideal choice.
Efficient
Listcrawler ts is an efficient web scraping library. This means that it uses resources wisely and can extract data from websites with minimal overhead. There are a number of factors that contribute to the efficiency of listcrawler ts, including:
- Resource usage: Listcrawler ts is designed to use as few resources as possible. This means that it can scrape large websites without putting a strain on your computer's resources.
- Concurrency: Listcrawler ts can scrape multiple pages concurrently. This means that it can extract data from websites much faster than other web scraping libraries.
- Built-in caching: Listcrawler ts has a built-in caching mechanism that stores the results of previous scrapes. This means that it can avoid re-scraping the same pages multiple times, which can save a significant amount of time.
The efficiency of listcrawler ts is a major advantage, especially for tasks that require the extraction of large amounts of data. If you need to extract data from a website quickly and efficiently, then listcrawler ts is the ideal choice.
Open-source
Listcrawler ts is an open-source web scraping library. This means that its source code is freely available to anyone, and it can be used and modified for any purpose. There are a number of benefits to using an open-source web scraping library, including:
- Transparency: Because the source code is freely available, you can be sure that listcrawler ts is not doing anything malicious. This is important, especially if you are using listcrawler ts to extract data from websites that contain sensitive information.
- Flexibility: Because you can modify the source code, you can customize listcrawler ts to meet your specific needs. This is useful if you need to extract data from websites that have a unique structure or that require special handling.
- Community support: Because listcrawler ts is open-source, there is a community of developers who can help you with any problems you encounter. This can be a valuable resource, especially if you are new to web scraping.
Overall, the open-source nature of listcrawler ts is a major advantage. It makes listcrawler ts more transparent, flexible, and supported than closed-source web scraping libraries.
Easy to use
Listcrawler ts is designed to be easy to use, even for beginners. It has a simple and intuitive API that makes it easy to get started with web scraping. Listcrawler ts also has a number of features that make it easy to use, such as:
- Well-documented: Listcrawler ts has extensive documentation that explains how to use the library. This documentation includes examples and tutorials that can help you get started with web scraping.
- Auto-generated selectors: Listcrawler ts can automatically generate CSS selectors for you. This makes it easy to target specific elements on a page, even if you don't know how to write CSS.
- Built-in error handling: Listcrawler ts has built-in error handling mechanisms that make it easy to handle errors that occur during scraping. This makes it easier to develop robust web scraping applications.
Overall, listcrawler ts is a user-friendly web scraping library that is easy to learn and use. This makes it a great choice for anyone who needs to extract data from websites.
Highly configurable
Listcrawler ts is a highly configurable web scraping library. This means that it can be customized to meet the specific needs of your web scraping project. For example, you can configure listcrawler ts to:
- Use different selectors to target specific elements on a page
- Set different timeouts for different requests
- Handle errors in different ways
- Use different caching mechanisms
The high level of configurability of listcrawler ts makes it a versatile tool that can be used for a wide variety of web scraping tasks. For example, you can use listcrawler ts to:
- Extract product data from an e-commerce website
- Extract news articles from a news website
- Extract social media data from a social media website
- Extract data from a PDF document
- Extract data from a web API
The high level of configurability of listcrawler ts is one of its key strengths. It makes listcrawler ts a great choice for anyone who needs to extract data from websites.
Supports XPath and CSS selectors
Listcrawler ts supports both XPath and CSS selectors for extracting data from websites. This is an important feature because it gives you the flexibility to target specific elements on a page, even if they are nested within other elements. For example, you can use XPath to target an element by its position in the DOM tree, or you can use CSS to target an element by its class or ID. This flexibility makes listcrawler ts a powerful tool for extracting data from websites, regardless of their structure.
XPath and CSS selectors are two of the most commonly used methods for selecting elements on a web page. XPath is a language that allows you to navigate the DOM tree of a web page and select elements based on their position or other criteria. CSS selectors are a set of rules that allow you to select elements on a web page based on their style properties. By supporting both XPath and CSS selectors, listcrawler ts gives you the flexibility to use the most appropriate method for selecting elements on a web page.
The ability to support XPath and CSS selectors is a major advantage of listcrawler ts. It makes listcrawler ts a more versatile and powerful tool for extracting data from websites. If you need to extract data from a website, then listcrawler ts is a great option.
Can automatically follow pagination links
Listcrawler ts includes the ability to automatically follow pagination links, which is an important feature for scraping websites that use pagination to display large amounts of data. Pagination links are links that lead to the next page of results, and they are often used by websites to display search results, product listings, and other types of data.
The ability to automatically follow pagination links is important because it allows listcrawler ts to extract data from all of the pages of a website, not just the first page. This is important for getting a complete picture of the data on a website, and it can be especially useful for websites that have a lot of data or that use pagination to display search results.
For example, if you are using listcrawler ts to scrape a website that sells products, the ability to automatically follow pagination links will allow you to extract data from all of the pages of products, not just the first page. This will give you a complete picture of the products that are available on the website, and it will allow you to make more informed decisions about which products to purchase.
Overall, the ability to automatically follow pagination links is an important feature of listcrawler ts. It allows you to extract data from all of the pages of a website, not just the first page, and it can be especially useful for websites that have a lot of data or that use pagination to display search results.
Supports concurrency
Listcrawler ts supports concurrency, which means that it can send multiple requests to the same website at the same time. This can significantly speed up the scraping process, especially for websites that have a lot of data or that are slow to respond. For example, if you are using listcrawler ts to scrape a website that has 100 pages of products, listcrawler ts can send 100 requests to the website at the same time. This will allow listcrawler ts to scrape the website much faster than if it had to send each request one at a time.
- Improved performance: Concurrency can significantly improve the performance of listcrawler ts, especially for websites that have a lot of data or that are slow to respond.
- Increased efficiency: Concurrency can also increase the efficiency of listcrawler ts by reducing the amount of time that it takes to scrape a website.
- Reduced costs: Concurrency can also reduce the costs of scraping a website by reducing the amount of time that it takes to complete the task.
Overall, the support for concurrency is a major advantage of listcrawler ts. It allows listcrawler ts to scrape websites faster, more efficiently, and at a lower cost. If you need to scrape a website, then listcrawler ts is a great option.
Has built-in retry and error handling mechanisms
Listcrawler ts has built-in retry and error handling mechanisms that make it more robust and reliable. This is important because it can help to prevent listcrawler ts from failing when it encounters errors, and it can also help to ensure that listcrawler ts can continue to scrape data even if the website is experiencing problems.
- Automatic retry: Listcrawler ts can automatically retry failed requests. This is useful for dealing with temporary errors, such as network outages or server timeouts. Listcrawler ts will automatically retry the request until it is successful, or until a specified number of retries has been reached.
- Error handling: Listcrawler ts has a built-in error handling mechanism that can catch and handle errors that occur during scraping. This can help to prevent listcrawler ts from crashing, and it can also help to ensure that listcrawler ts can continue to scrape data even if the website is experiencing problems.
The built-in retry and error handling mechanisms of listcrawler ts make it a more robust and reliable web scraping library. This is important for anyone who needs to extract data from websites, as it can help to prevent listcrawler ts from failing when it encounters errors, and it can also help to ensure that listcrawler ts can continue to scrape data even if the website is experiencing problems.
To extract product data from an e-commerce website
Extracting product data from an e-commerce website is a common task for businesses that want to track prices, compare products, or build their own product databases. Listcrawler ts is a powerful web scraping library that can be used to extract product data from e-commerce websites. It is fast, efficient, and easy to use, and it supports a variety of features that make it ideal for extracting product data, including:
- XPath and CSS selectors: Listcrawler ts supports both XPath and CSS selectors for extracting data from websites. This makes it easy to target specific elements on a page, even if they are nested within other elements.
- Automatic pagination: Listcrawler ts can automatically follow pagination links on a website, making it easy to extract data from multi-page websites.
- Concurrency: Listcrawler ts can scrape multiple pages concurrently, making it faster to extract data from large websites.
- Built-in retry and error handling mechanisms: Listcrawler ts has built-in retry and error handling mechanisms, making it more reliable and robust.
Listcrawler ts is a powerful tool that can be used to extract product data from a variety of e-commerce websites. It is easy to use, efficient, and highly configurable. If you need to extract product data from an e-commerce website, then listcrawler ts is a great option.
Here are some examples of how listcrawler ts can be used to extract product data from e-commerce websites:
- To extract product names, prices, and descriptions from an e-commerce website.
- To track the prices of products on an e-commerce website over time.
- To compare the prices of products on different e-commerce websites.
- To build a database of products from an e-commerce website.
Listcrawler ts is a versatile tool that can be used for a variety of purposes. It is a great option for anyone who needs to extract data from an e-commerce website.
To extract news articles from a news website
Extracting news articles from a news website is a common task for journalists, researchers, and anyone who wants to stay informed about current events. Listcrawler ts is a powerful web scraping library that can be used to extract news articles from news websites. It is fast, efficient, and easy to use, and it supports a variety of features that make it ideal for extracting news articles, including:
- XPath and CSS selectors: Listcrawler ts supports both XPath and CSS selectors for extracting data from websites. This makes it easy to target specific elements on a page, even if they are nested within other elements.
- Automatic pagination: Listcrawler ts can automatically follow pagination links on a website, making it easy to extract data from multi-page websites.
- Concurrency: Listcrawler ts can scrape multiple pages concurrently, making it faster to extract data from large websites.
- Built-in retry and error handling mechanisms: Listcrawler ts has built-in retry and error handling mechanisms, making it more reliable and robust.
Here are some examples of how listcrawler ts can be used to extract news articles from news websites:
- To extract the headlines, authors, and publication dates of news articles from a news website.
- To track the coverage of a particular topic across multiple news websites.
- To build a database of news articles from a news website.
Listcrawler ts is a powerful tool that can be used to extract news articles from a variety of news websites. It is easy to use, efficient, and highly configurable. If you need to extract news articles from a news website, then listcrawler ts is a great option.
To extract social media data from a social media website
Social media data is a valuable source of information for businesses and researchers. It can be used to track trends, analyze customer sentiment, and identify potential customers. Listcrawler ts is a powerful web scraping library that can be used to extract social media data from a variety of social media websites. It is fast, efficient, and easy to use, and it supports a variety of features that make it ideal for extracting social media data, including:
- XPath and CSS selectors: Listcrawler ts supports both XPath and CSS selectors for extracting data from websites. This makes it easy to target specific elements on a page, even if they are nested within other elements.
- Automatic pagination: Listcrawler ts can automatically follow pagination links on a website, making it easy to extract data from multi-page websites.
- Concurrency: Listcrawler ts can scrape multiple pages concurrently, making it faster to extract data from large websites.
- Built-in retry and error handling mechanisms: Listcrawler ts has built-in retry and error handling mechanisms, making it more reliable and robust.
Here are some examples of how listcrawler ts can be used to extract social media data from social media websites:
- To extract the names, locations, and interests of users on a social media website.
- To track the number of likes, shares, and comments on a social media post.
- To identify potential customers for a business.
Listcrawler ts is a powerful tool that can be used to extract social media data from a variety of social media websites. It is easy to use, efficient, and highly configurable. If you need to extract social media data from a social media website, then listcrawler ts is a great option.
To extract data from a PDF document
For many organizations, extracting data from large PDF documents is a time-consuming process that may necessitate the use of expensive commercial solutions. However, by leveraging the latest advancements in web scraping technology, retrieving information from PDF documents can be made far more accessible.
- Flexibility
Unlike traditional PDF extraction methods, which can be rigid and inflexible, web scraping tools offer a greater degree of customization, allowing for tailored solutions to meet specific requirements. - Automation
The automation capabilities of web scraping tools enable the extraction of data from multiple PDF documents simultaneously, eliminating the need for manual labor and repetitive tasks. - Accuracy
Advanced web scraping tools employ sophisticated algorithms that ensure high accuracy in data extraction, minimizing the risk of errors and inconsistencies. - Cost-effectiveness
In comparison to commercial PDF extraction solutions, web scraping tools offer a cost-effective alternative, providing organizations with a budget-friendly option for data extraction.
To conclude, leveraging the capabilities of web scraping technology, as exemplified by tools like listcrawler ts, offers many advantages for extracting data from PDF documents. These advantages include increased flexibility, automation, accuracy, and cost-effectiveness. By adopting these tools, organizations can streamline their data extraction processes, enhance efficiency, and gain valuable insights from their PDF documents.
To extract data from a web API
In the realm of data acquisition, extracting data from web APIs has become increasingly crucial for businesses and organizations seeking to integrate external data sources and enhance their operations. Listcrawler ts, as a robust web scraping library, seamlessly integrates with web APIs to facilitate efficient and reliable data extraction.
Web APIs, also known as application programming interfaces, provide a standardized interface for interacting with various applications and services. They allow for the exchange of data and functionality between different systems, enabling the retrieval of valuable information from third-party sources. Listcrawler ts plays a pivotal role in harnessing the potential of web APIs by offering a comprehensive set of features tailored for data extraction tasks.
One of the key advantages of using listcrawler ts to extract data from web APIs is its ability to automate the process. Manual data extraction can be a tedious and error-prone task, especially when dealing with large datasets or frequent API calls. Listcrawler ts automates the entire process, including sending API requests, parsing responses, and extracting the necessary data. This automation significantly reduces the time and effort required for data extraction, allowing organizations to focus on more strategic tasks.
Furthermore, listcrawler ts provides advanced features that enhance the reliability and accuracy of data extraction from web APIs. It supports various authentication mechanisms, ensuring secure access to protected APIs. Additionally, listcrawler ts offers built-in error handling mechanisms that can automatically retry failed requests and handle unexpected responses, ensuring that data extraction is consistent and reliable.
In summary, listcrawler ts plays a vital role in extracting data from web APIs by providing automation, reliability, and accuracy. Its integration with web APIs empowers businesses and organizations to seamlessly incorporate external data sources into their systems, gain valuable insights, and make informed decisions.
Frequently Asked Questions about Listcrawler TS
This section aims to provide clear and informative answers to frequently asked questions regarding Listcrawler TS. These questions address common concerns and misconceptions surrounding the library to enhance understanding and facilitate its effective utilization.
Question 1: What are the key advantages of using Listcrawler TS?
Listcrawler TS offers several key advantages, including its speed, efficiency, open-source nature, ease of use, high level of configurability, and comprehensive support for web scraping tasks. These advantages make it a valuable tool for extracting data from websites.
Question 2: How does Listcrawler TS ensure the accuracy of extracted data?
Listcrawler TS employs advanced algorithms and robust error handling mechanisms to ensure the accuracy of extracted data. It can automatically retry failed requests and handle unexpected responses, minimizing the risk of data loss or inconsistencies.
Question 3: What types of websites can Listcrawler TS be used to scrape data from?
Listcrawler TS is a versatile tool that can be used to scrape data from a wide range of websites, including e-commerce websites, news websites, social media platforms, and even websites with complex structures or that require special handling.
Question 4: How does Listcrawler TS handle pagination and AJAX-based websites?
Listcrawler TS has built-in support for automatic pagination, enabling it to extract data from websites with multiple pages. Additionally, it can handle AJAX-based websites by utilizing headless browsers to simulate real-world user interactions.
Question 5: What is the learning curve associated with using Listcrawler TS?
Listcrawler TS is designed to be user-friendly and accessible to individuals with varying levels of technical expertise. Its well-documented API and extensive resources make it easy to learn and implement, enabling users to quickly achieve their web scraping goals.
Question 6: How does Listcrawler TS compare to other web scraping libraries?
Listcrawler TS stands out among other web scraping libraries due to its combination of speed, efficiency, flexibility, and reliability. Its open-source nature, coupled with its active community support, further enhances its value proposition.
By addressing these frequently asked questions, we aim to provide a deeper understanding of Listcrawler TS and its capabilities. Whether you are a seasoned web scraping professional or just starting out, Listcrawler TS offers a powerful and versatile solution for your data extraction needs.
For further information and resources, please refer to the official Listcrawler TS documentation and community forums.
Listcrawler TS Tips
Listcrawler TS is a powerful and versatile web scraping library that can be used to extract data from a wide range of websites. Here are some tips to help you get the most out of Listcrawler TS:
Tip 1: Use the right selectorsThe selectors you use to target elements on a page will have a big impact on the performance of your scraper.XPath selectors are generally more powerful than CSS selectors, but they can also be more complex to write.If you're not sure which selector to use, start with CSS selectors and see if they work. If not, you can switch to XPath selectors. Tip 2: Use pagination
Many websites use pagination to break up their content into multiple pages.If you want to scrape all of the content on a website, you'll need to use pagination to follow the links to the next page and scrape the content from that page as well. Tip 3: Handle errors
It's inevitable that you'll encounter errors when scraping data from websites.Listcrawler TS has a number of built-in error handling mechanisms that can help you deal with these errors. Tip 4: Use concurrency
Concurrency can significantly improve the performance of your scraper.Listcrawler TS supports concurrency, so you can scrape multiple pages at the same time. Tip 5: Use caching
Caching can help you improve the performance of your scraper by storing the results of previous scrapes.This can be especially useful if you're scraping the same website multiple times.
By following these tips, you can improve the performance, reliability, and accuracy of your web scraping projects.
For more information on Listcrawler TS, please refer to the official documentation.
Conclusion
Listcrawler TS is a versatile and easy to use web scraping library that can be utilized for various data extraction tasks. Its speed, efficiency, and flexibility, coupled with its ability to handle complex websites and utilize advanced features like pagination and error handling, make it a valuable asset for developers. Additionally, its open-source nature and extensive community support contribute to its appeal as a reliable and cost-effective solution.
As the digital landscape continues to expand and data becomes increasingly crucial, Listcrawler TS emerges as a powerful tool for harnessing valuable insights from the vast ocean of online information. By embracing its capabilities, developers and organizations can streamline their web scraping processes, enhance their decision-making, and drive innovation.




